고정 헤더 영역
상세 컨텐츠
본문
오늘은 컬렉션 프레임웍에 대해서 공부하는데 내용이 굉장히 방대하다. 그러므로 개념위주로 글을 쓰겠다. 자바에서 이에 대한 코드는 이미 구현이 되어 있어 쉽게 찾을 수 있다. 그러므로 개념위주로 살펴보자
1. 컬렉션 프레임 웍 (Collection Framework)
The Java collections framework (JCF) is a set of classes and interfaces that implement commonly reusable collection data structures.
- 위키
즉 데이터 군을 다루고 표현하기 위한 단일화된 구조를 제공하여 재사용성을 높여 준다. 라고 볼 수 있다.
간단하게 먼저 그림을 보면


-출처 : 나무 위키
나무위키에 너무 좋은 그림이 있어서 가져 왔다.
컬렉션 프레임웍의 전체적인 구조도를 한눈에 보여준다
아직 컬렉션 프레임웍을 잘모르는 사람은 어지러울수 있지만 위에서 아래로 차례대로 잘 보면 절대 어렵지 않다(그림의 화살표는 상속&구현을 나타냄)
collection 과 다르게 Map은 따로 그림이 표현되어져 있는데 , 이는 List 와 Set의 공통적인 부분만 따로 빼서 인터페이스를 만든게 Collection 이고 Map은 '데이터 군'을 다르게 다루기 때문에 따로 빼놓은 것이다.
먼저 Collection을 보면
List 와 Set으로 나뉘어져 있는데 여기서 공통정인 부분을 따로 뺏다고 앞서 설명 했다.
여기서 공통적인 부분은 매서드라고 생각 하면 된다. 참고로 https://docs.oracle.com/javase/7/docs/api/ 에 들어가서 collection의 매서드 부분을 보면 무엇이 있는지 알 수 있다. 그중 몇가지를 살펴 보면
boolean add(E e)
Appends the specified element to the end of this list (optional operation).
void clear()
Removes all of the elements from this list (optional operation).
boolean equals(Object o)
Compares the specified object with this list for equality.
E get(int index)
Returns the element at the specified position in this list.
boolean isEmpty()
Returns true if this list contains no elements.
ListIterator<E> listIterator()
Returns a list iterator over the elements in this list (in proper sequence).
E remove(int index)
Removes the element at the specified position in this list (optional operation)
int size()
Returns the number of elements in this list.
Object[] toArray()
Returns an array containing all of the elements in this list in proper sequence (from first to last element).
이 정도? 는 알고 있으면 좋을 것 같다. 설명은 전부 설명 되어 있으니 생략 하겠다. 참고로 <E>는 제네릭스인데 단순하게 일단은 이 매서드를 호출한 객체를 반환한다고만 알고 넘어가자
그리고 이후 컬렉션에서 나눠지는것 중 세가지를 설명 하자면
List는 순서가 있는 '데이터 군' 이며 중복을 허용 한다
Set은 순서가 없는 '데이터 군' 이며 중복을 허용 하지 않는다.
Map은 'key'와 'value'의 쌍으로 이루어 졌으며 순서가 없는 '데이터군' 이다 여기서 key는 중복을 허용하지 않지만 value는 중복을 허용한다.
(key는 여러분이 생각하는 key와 같다 . 무언가 접근하기 위한 key 라고 생각 하면 된다)
2. List
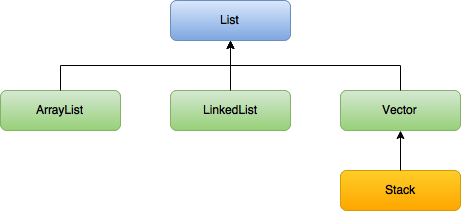
List는 interface 이며 이를 구현하는 클래스들은 모든 매서드를 구현 해줘야 한다.
List interface는 앞서 말했듯이 저장순서가 유지되며 중복을 허용 한다고 했다. 그리고 이러한 특성은 이를 구현하는 모든 클래스들에 해당되어진다.
2.1 ArrayList
ArrayList를 설명 하자면
이는 vector 클래스를 개선한 것으로 기능적으로 동일하다. ArrayList는 내부적으로 Object 배열을 이용하기 때문에 배열적인 특성을 갖고 있다. ( 아니 배열과 다름없다! )

인덱스의 순서가 0,1,2,3...순서대로 저장되며 만약 배열의 공간이 꽉찬다면 기존 배열의 크기가 변하는 것이 아니라 새로운 더 큰 배열을 생성하고 그곳에 모든 데이터군을 복사하여 사용한다. 즉 배열에 다이나믹적인 특성을 더한거 뿐이다. 이러한 배열적 특성은 후에 속도(Slow)에 영향을 끼친다.
2.2 LinkeList
다음으로 LinkedList를 살펴보자
앞서 본 배열 형태의 리스트는 구조가 간단하며 단순하게 데이터를 읽는 것에 있어 속도가 빠르다.
하지만 크기를 변경 할수 없고(새로운 배열 생성) , 비순차적 데이터에 대해서 추가/삭제에 시간이 많이 걸린다.
왜냐 가장 마지막 인덱스에 대해서 추가/삭제는 빠르다. 하지만 중간 데이터에 대해서 추가/삭제를 하려면 빈자리를 만들거나 삭제를 위해 새로운 배열을 생성하고 이후 복사과정을 거쳐야 하기 때문에 속도가 느려진다.

이러한 단점을 극복하기 위해서 나온것이 LinkedList 이다. 다만 단점이 있는데 배열은 연속적인 데이터로 존재한다 즉 배열의 주소가 일정하게 증가한다.
하지만 LinkedList는 불연속적이며 단지 연결 형태로 되어있다. 이는 자료구조를 공부한 사람이라면 알것이다. 이 때문에 데이터를 읽는 속도는 느릴 수 있다.( 주소가 뒤죽 박죽일 수 있기 때문 예 ) 0x0 <-> 0x4 <-> 0x300 <-> 0x500 <-> 0x204 .... )
LinkedList는 단순하게 연결을 끊거나 이어주는 것으로 삽입 삭제를 구현하기 때문에 배열보다 빠르며 굉장히 쉽다.
LinkedList 에 대한 매서드도 굉장히 많으므로 api를 참고하도록 하자.(https://docs.oracle.com/javase/9/docs/api/index.html?overview-summary.html)
2.3 Stack 과 Queue


왼쪽 그림은 Stack을 보여주고 오른쪽 그림은 Queue를 보여준다.
스택은 데이터가 들어오면 위에 쌓이고 데이터를 꺼낼 때도 위에서 꺼내진다. 그래서 스택을 Last In First Out 마지막에 들어온것이 처음으로 나간다.
큐는 First in First Out 처음에 들어온것이 처음으로 나간다.
맨위의 계층 그림을 보면 Stack은 Vector(ArrayList 같은 ) 기반 이고 Queue는 LinkedList기반으로 이루어져 있는 것을 볼 수있다.
이는 각각의 특성에 맞게끔 구현이 되서 그렇다
Stack의 경우 순차적(위에서 부터 추가/삭제)으로 추가 되어지고 삭제 되어지기 때문에 ArrayList 형태가 적합하다. 하지만 Queue의 경우 위에 쌓이지만 나가는 것은 가장 아래에 있는 것이 나간다. 이를 ArrayList로 구현하게 되면 가장 아래에 있는 데이터를 추출 할 때마다 새로운 배열을 생성해줘야 한다. 그렇기 때문에 LinkedLsit 형태로 구현하는 것이 더 좋기 때문에 가장 맨위 그림과 같은 계층도가 생긴 것이다.
3. Set
Set 인터페이스중 가장 대표정인 HashSet을 알아보자

이러한 상속 관계를 지니고 있으며 앞서 말한 중복된 요소를 가지지 않는 순서가 없는 데이터 군이다.
일단 중복된 요소를 어떻게 검출 하는가를 간단하게 알아보고 자세하게는 HashMap을 소개하면서 하겠습니다.
HashSet은 add 매서드로 요소를 추가히전에 기존의 저장된 요소와 비교과정을 거친다. 여기서 비교 과정을 거칠 때 넣을려는 해당 객체에 대한 equals 와 hasCode 를 호출 하게 된다. 즉 HashSet의 저장요소로 사용하려는 객체는 반드시 두 매서드를 정의 해놔야 한다점만 일단 알고 있자.
4. Map
다음으로 Map 인터페이스를 알아보자 Map은 기존 Collection 인터페이스와는 다르게 데이터를 관리한다.
Map은 Key(키)와 Value(값)을 묶어서 하나의 Entry로 저장한다.
하나의 Entry로 저장 한다는 말이 생소 할수 있는데 이는 코드를 보면 알 수 있다.
코드의 일부이다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
}
|
cs |
저런식으로 내부클래스로 Entry로 관리하게 된다. 이는 객체지향적 특성을 보여준다고 할 수 있다.
key는 컬렉션 내에서 유일 해야하며 value는 데이터의 중복을 허용한다는 점이 있다.
이를 반드시 인지하고 다음 코드르 보자
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
|
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map.Entry;
import java.util.Set;
public class HashTest {
public static void main(String[] args) {
PersonList personList = PersonList.getInstance();
personList.addPerson("친구","아이유","IU@naver.com");
personList.addPerson("친구","수지","SuJi@naver.com");
personList.addPerson("친구","정은지","JYJ@naver.com");
personList.addPerson("가족","엄마","UmMa@naver.com");
personList.addPerson("가족","아빠","ABba@naver.com");
personList.addPerson("서점","SuJum@naver.com");
personList.print();
}
}
class PersonList extends HashMap<String,HashMap<String, String>> {
private static PersonList personList = new PersonList();
public static PersonList getInstance() {
return personList;
}
void addPerson(String group , String name , String mail) {
personList.addGroup(group);
HashMap<String, String> groupMap = personList.get(group);
groupMap.put(mail, name);
}
void addPerson(String name ,String mail) {
personList.addPerson("기타",name,mail);
}
private void addGroup(String group) {
if(!personList.containsKey(group))
personList.put(group, new HashMap<String,String>());
}
void print() {
Set<Entry<String, HashMap<String, String>>> set = personList.entrySet();
Iterator<Entry<String, HashMap<String, String>>> it = set.iterator();
while(it.hasNext()) {
Entry<String, HashMap<String, String>> e = it.next();
Set<Entry<String, String>> subSet = e.getValue().entrySet();
Iterator<Entry<String, String>> it2 = subSet.iterator();
System.out.println("---"+e.getKey()+"리스트---");
while(it2.hasNext()) {
Entry<String, String> e2 = it2.next();
System.out.println("mail : "+ e2.getKey()+ " name : " + e2.getValue());
}
System.out.println();
}
}
}
|
cs |
이 코드는 간단하게 친구목록? 리스트를 등록하는 것이다 다만 이를 HashMap 형태로 짜본 것이다. 또 싱글톤패턴도 공부할 겸 추가했다.
이 해시 테이블은
group HashMap 형태로 되어 있고 이후에 HashMap 내부에 다시 name mail이 들어가게 된다. 여기서 mail을 키값으로 하였는데 이는 이름의 경우 중복 될수 있으므로 키값으로 설정할 수없다.
5. 해싱과 해시함수
앞서 언급했던 hashCode 와 해싱에 대해 자세하게 알아보자.
먼저 해싱이란 해시함수(hash function)을 이용해 데이터를 해싱테이블에 저장하고 검색하는 기법을 말한다. 여기서 이 해싱을 구현한 클래스가 HashSet, HashMap이 있다. 이 해싱을 구현한 인터페이스는 해시함수를 이용해 데이터가 저장되어 있는곳을 알려주기 때문에 다량의 데이터 중에서도 원하는 데이터를 빠르게 찾을 수 있다.
해싱에서 사용하는 자료구조는 배열과 링크드리스트의 조합으로 되어 있다.
출처 : http://faculty.cs.niu.edu/~freedman/340/340notes/340hash.htm
되게 설명이 잘 되어져있다.

여기서 hashfunction은 왼쪽의 나누기 과정으로 볼수 있고 이것의 결과값이 해당 해시코드이다.
그림에서 보면 10 과 18일 동일한 해시코드를 갖고 있는 것을 볼수 있는데 이를 '충돌'이라고 한다. 그리고 이를 chaining으로 연결한 모습을 보여준다.
더보기
Hashing with Chains
When a collision occurs, elements with the same hash key will be chained together. A chain is simply a linked list of all the elements with the same hash key.
The hash table slots will no longer hold a table element. They will now hold the address of a table element.
해싱에 대해서 어느정도 설명이 되어진것 같다.
HashMap 역시 해싱을 구현 했으므로 이러한 과정을 거친다. Object클래스에 정의된 hashCode()를 해시함수로 이용하며 객체의 주소를 이용하는 알고리즘으로 구성 되어져 있다.
앞서 말했듯이 hashing을 구현한 클래스는 반드시 equals 와 hashcode()를 구현해야만 한다고 했고 이를 통해 중복성을 검사한다고 했다.
이에 대해 자세하게 설명 하겠다. 먼저 코드를 보자
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
|
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
public class Person {
private int id;
private String name;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public boolean equals(Object obj) {
if (obj == null) {
return false;
}
if (this.getClass() != obj.getClass()) {
return false;
}
if (this == obj) {
return true;
}
Person that = (Person) obj;
if (this.name == null && that.name != null) {
return false;
}
// 느슨한 equals
if(this.name.equals(that.name)){
return true;
}
/* 빡빡한 equals
if (this.id == that.id && this.name.equals(that.name)) {
return true;
}
*/
return false;
}
@Override
public int hashCode() {
final int prime = 2;
int result = 1;
result = prime * result + ((name == null) ? 0 : name.hashCode());
result = prime * result + id;
return result;
}
public static void main(String[] args) {
Person p1 = new Person();
p1.setId(1);
p1.setName("Sam");
Person p2 = new Person();
p2.setId(2);
p2.setName("Sam");
Map<Person, Integer> map = new HashMap<Person, Integer>();
map.put(p1, 2);
map.put(p2, 3);
System.out.println("----------------------------------");
System.out.println("eqauls(키값)은 같나? : " + p1.equals(p2));
System.out.println("해시코드값 같나? : " + (p1.hashCode() == p2.hashCode()));
System.out.println("해시테이블 사이즈 : "+map.size());
System.out.println("----------------------------------");
}
}
|
cs |
결과:
----------------------------------
eqauls(키값)은 같나? : true
해시코드값 같나? : false
해시테이블 사이즈 : 2
----------------------------------
equals의 값이 true인데도 불구하고 해시코드값이 달라 해싱과정에서 다른 데이터로 구분하여 저장되어졌다.
69번 라인을 p2.setId(1); 로 고쳐보자
----------------------------------
eqauls(키값)은 같나? : true
해시코드값 같나? : true
해시테이블 사이즈 : 1
----------------------------------
둘다 true가 나오고서야 중복으로 인식하고 하나만 배정되어져 있다.
이번에는 57번 라인을 주석처리하고 p1.setName("Saam"); 으로 고쳐보자
----------------------------------
eqauls(키값)은 같나? : false
해시코드값 같나? : true
해시테이블 사이즈 : 2
----------------------------------
이번에는 키값은 다르지만 해시코드값이 같아 서로 다른 데이터로 인식하것을 볼 수있다.
이는 애초에 키가 다르니 서로다른 데이터로 취급해도 상관 없다. 다만 키가 달라도 해쉬코드가 동일 할수 있다는것을 보여준다.(물론 이럴경우 성능 저하를 초래한다.)
위 세가지의 경우를 보고 결론을 내리자면
equals가 true가 나올경우에는 반드시 hashCode값 역시 true가 나오게끔 해줘야 된다는것 그렇지 않으면 같은 키값임에도 중복처리로 되지 않고 서로 다른 데이터가 된다는것 이다.
참고). Enumeration , Iterator , ListIterator
이 세 개 모두 컬렉션에 저장된 요소를 접근하는데 사용 된다. 다만 Enumeration , Iterator , ListIterator 순으로 개선 되어진것이다.
boolean hasNext()
Returns true if the iteration has more elements.
E next()
Returns the next element in the iteration.
void remove()
Removes from the underlying collection the last element returned by this iterator (optional operation).
이 세가지가 가장 많이 쓰여지므로 반드시 알아 둘 필요가 있다
자바의 정석 코드중 되게 좋은 코드가 있어서 올린다.(뜬금없지만 수많은 책중 JAVA의 정석 무조건 추천함 열의가 대단하심 )
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
|
import java.util.*;
public class MyVector2 extends MyVector implements Iterator {
int cursor = 0;
int lastRet = -1;
public MyVector2(int capacity) {
super(capacity);
}
public MyVector2() {
this(10);
}
public String toString() {
String tmp = "";
Iterator it = iterator();
for(int i=0; it.hasNext();i++) {
if(i!=0) tmp+=", ";
tmp += it.next(); // tmp += next().toString();
}
return "["+ tmp +"]";
}
public Iterator iterator() {
cursor=0; // cursor와 lastRet를 초기화 한다.
lastRet = -1;
return this;
}
public boolean hasNext() {
return cursor != size();
}
public Object next(){
Object next = get(cursor);
lastRet = cursor++;
return next;
}
public void remove() {
// 더이상 삭제할 것이 없으면 IllegalStateException를 발생시킨다.
if(lastRet==-1) {
throw new IllegalStateException();
} else {
remove(lastRet);
cursor--; // 삭제 후에 cursor의 위치를 감소시킨다.
lastRet = -1; // lastRet의 값을 초기화 한다.
}
}
} // class
|
cs |
이 코드를 잘 분석하면 iterator가 어떻게 돌아가는지는 이해가 될것이다.
. ArrayList와 Map 혼합해서 사용하기
*) 주의
HashMap의 key를 사용해서 접근하도록 한다. 간혹 values를 이용해 바로 value에 접근하는 경우가 있는데... 좋지못하다고 생각함..
그냥 value로 접근해서 쓸 경우에는 그냥 다른 collection을 사용하자
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Iterator;
public class test {
public static void main(String[] args) {
ArrayList<HashMap<String, String>> list = new ArrayList<HashMap<String, String>>();
HashMap<String, String> map = new HashMap<String, String>();
map.put("dong1", "정왕1동");
map.put("dong2", "정왕2동");
map.put("dong3", "정왕3동");
HashMap<String, String> map2 = new HashMap<String, String>();
map2.put("dong4", "정왕4동");
map2.put("dong5", "마전동");
map2.put("dong6", "정왕6동");
list.add(map);
list.add(map2);
HashMap<String, String> take = null;
for (int i = 0; i < list.size(); i++) {
take = list.get(i);
Iterator it = take.keySet().iterator();
while (it.hasNext()) {
String key = (String) it.next();
if ("마전동".equals(take.get(key)))
System.out.println("key :" + key + " value :" + take.get(key));
}
}
}
}
|
cs |
'JAVA' 카테고리의 다른 글
| 자바 공부 <8> - 제네릭스(Generics) (2) | 2018.07.27 |
|---|---|
| 자바공부<7> - JAVA IO (1) | 2018.07.24 |
| parseDouble과 parseInt의 구조적 차이 (판정 유무) (1) | 2018.07.12 |
| 자바공부<5> - 인터페이스 (1) | 2018.07.10 |
| 자바공부<4> - 다형성 (0) | 2018.07.09 |




